

O Seedance 2.0 acaba de mostrar um salto prático para quem trabalha com cinematics, trailers e prototipação: o novo modo Audio Reference permite enviar uma única imagem do personagem + um arquivo de áudio para a IA gerar um clipe com lip sync (sincronização labial) e performance, incluindo movimentos corporais e detalhes visuais que normalmente exigiriam rig, captura ou animação manual.
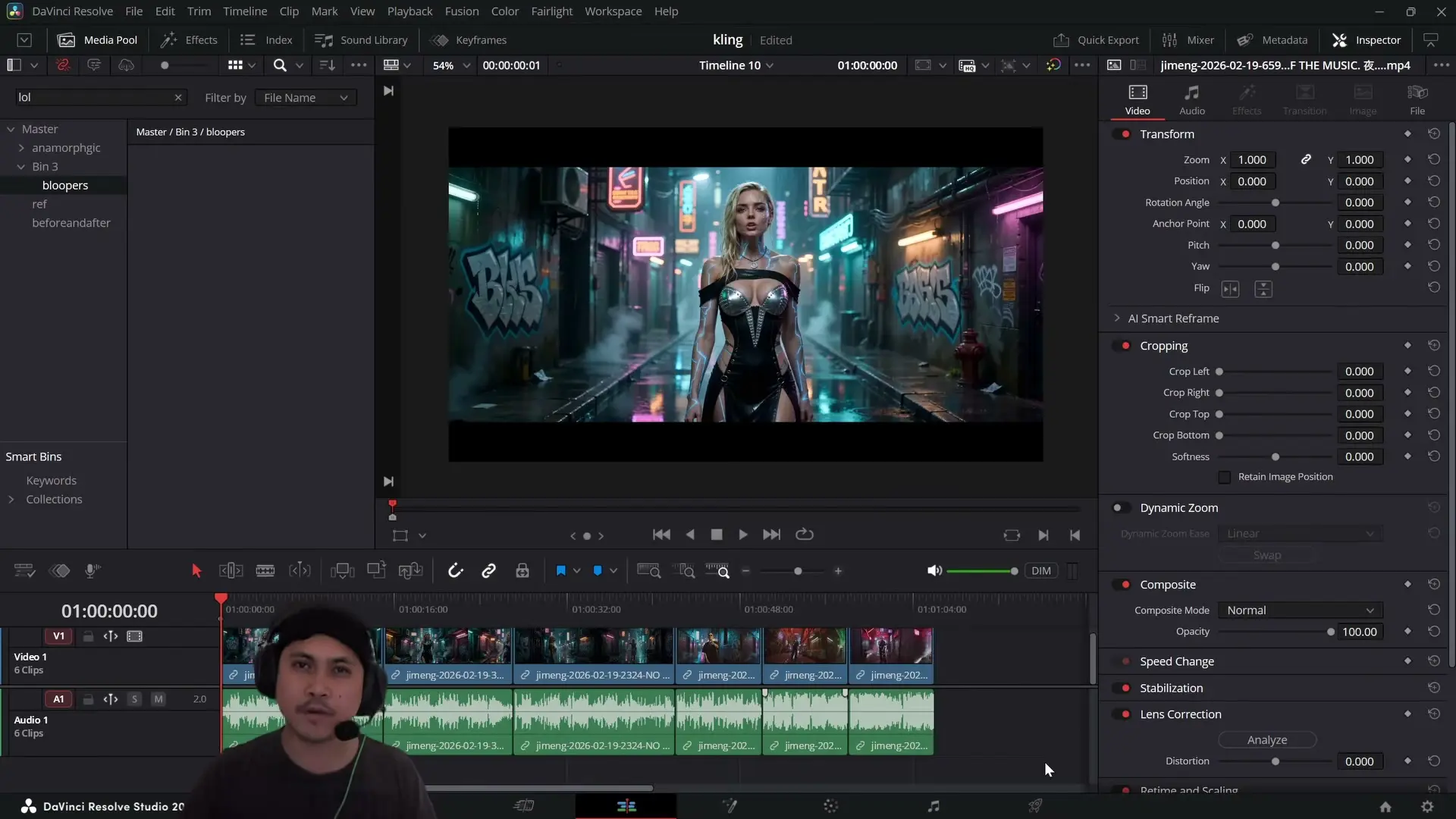
No vídeo, Jay (JSFILMZ) descreve um fluxo direto: ele faz upload da foto do personagem, adiciona o áudio e instruí o Seedance 2.0 a usar aquele som como base para o lip sync. Na prática, isso transforma um “still” (imagem estática) em uma atuação animada com boca, cabeça, mãos e postura reagindo ao som.
O primeiro teste chama atenção por um comportamento inesperado: ao invés de reproduzir fielmente a letra, o resultado sai com palavras diferentes — mas ainda assim preservando o timbre do cantor do áudio original. Jay levanta duas hipóteses: filtragem (o sistema alterando letras por segurança/moderação) ou falha de entendimento do vocal, levando a IA a “inventar” palavras.
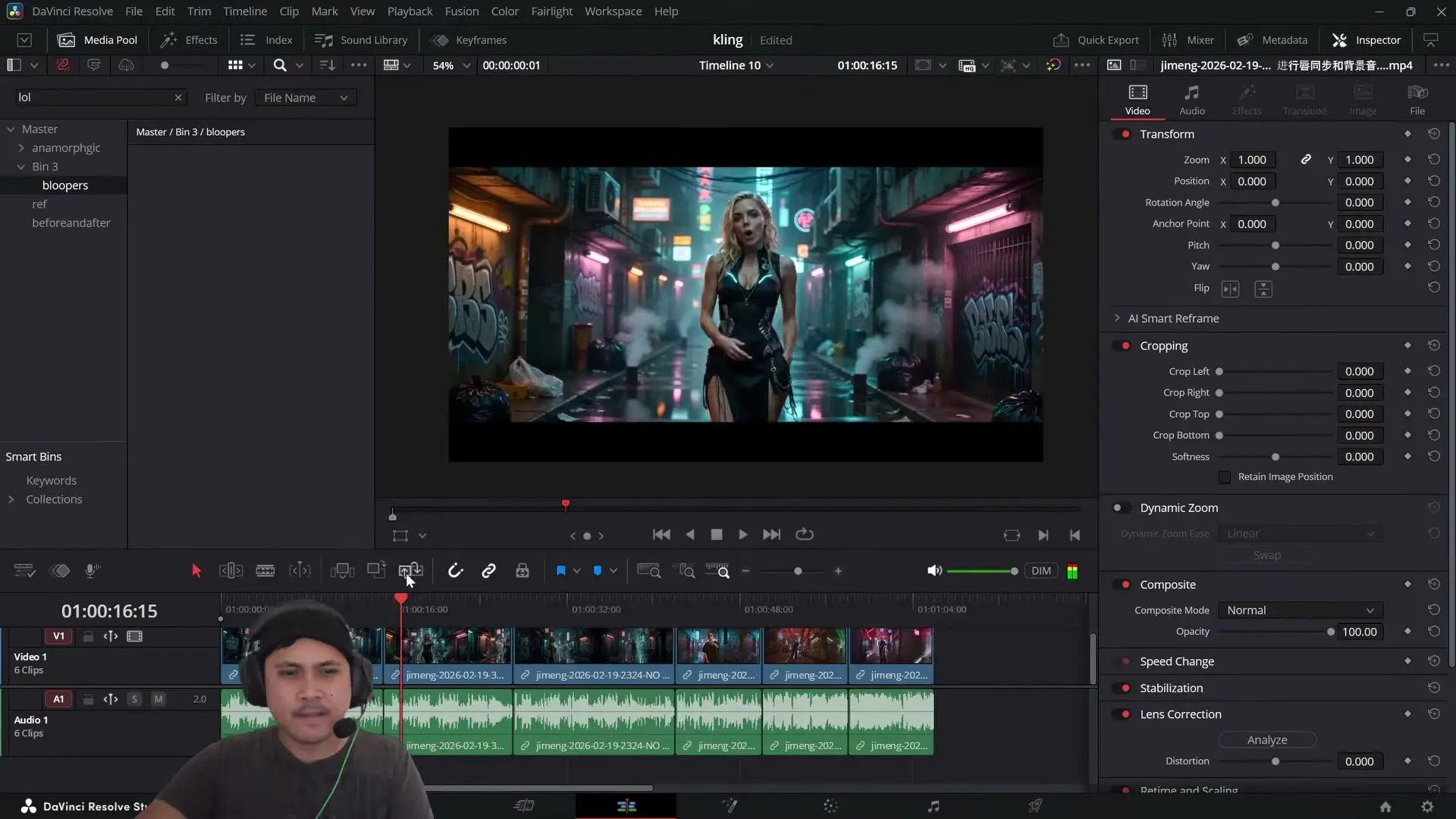
Mesmo com a troca de palavras, o que impressiona tecnicamente é a leitura do áudio: segundo ele, o Seedance 2.0 parece isolar os vocais (separar voz do instrumental, como um “acapella”) e reencaixar uma nova letra mantendo uma assinatura vocal parecida com a do cantor da referência. Para pipelines de conteúdo, isso sugere uma etapa única capaz de combinar atuação + fala/canto sem passar por ferramentas tradicionais de edição de áudio, dublagem e animação facial.
Em seguida, ele força uma mudança deliberada: pede para a IA alterar toda a letra para japonês. O resultado é descrito como “insano”, ainda que ele ressalte que a qualidade visual de um clipe gerado a partir de uma única imagem não é o objetivo final — “qualidade e resolução vêm depois”. Em termos de produção, isso aponta para um uso claro: pré-visualização (previs), quando você quer validar ideia, timing e presença de cena antes de gastar horas em assets e render final.
Jay também comenta elementos de movimento que aparecem nos clipes, como gestos de mão, apontamentos, inclinação de ombro, animação de acessórios (correntes) e até comportamento de tecido molhado em uma camiseta. Para quem trabalha com Unreal Engine e cinematics, são justamente esses “micro-sinais” que vendem a atuação — e que costumam custar caro em keyframe ou mocap.
O último exemplo muda a regra: ele não fornece áudio e apenas descreve a situação (“um cara rimando em um beco cyberpunk”). O sistema gera uma performance falada/cantada do zero, com o criador destacando um detalhe de renderização percebido na cena: reflexos e transparência em óculos, além de uma tentativa do modelo de manter coerência de iluminação quando o personagem vira o rosto (a luz “fica” no lugar esperado, mesmo sem entender 3D perfeitamente).
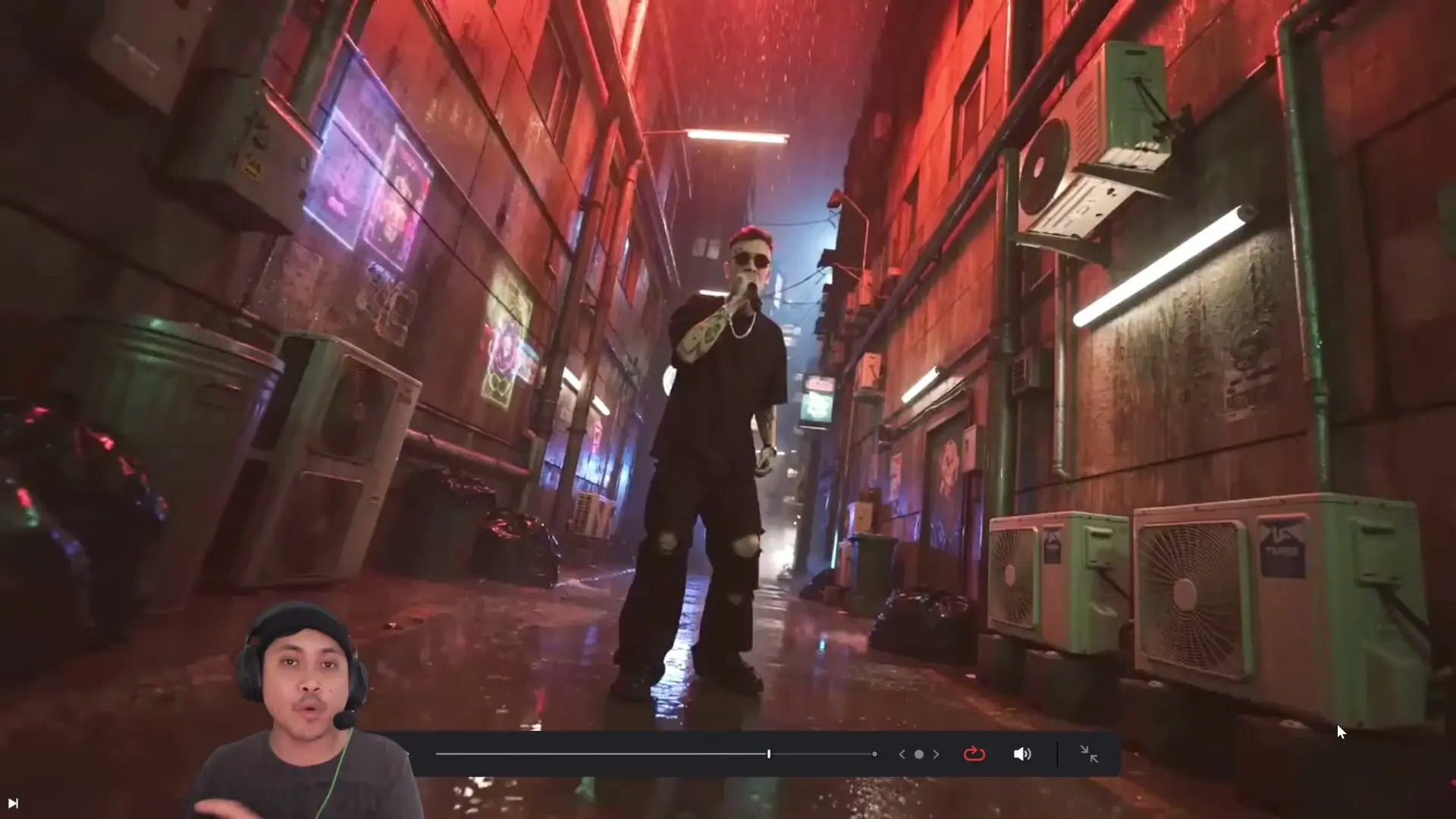
Para desenvolvimento de jogos, a implicação é direta: ferramentas assim encurtam o caminho entre roteiro e cena jogável. Você prototipa diálogos, trechos musicais e acting com poucos insumos (imagem + som ou só prompt), avalia ritmo e staging e só então decide onde investir em rig, captura facial e animação final.
Assista ao vídeo para ver os clipes completos, ouvir as variações geradas e entender exatamente como o Audio Reference está se comportando nos testes reais.
Fonte: JSFILMZ